


Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
村松 一弘; 齋 和憲*
JAERI-Data/Code 2002-017, 101 Pages, 2002/08
 JAERI-Data-Code-2002-017.pdf:5.65MB
JAERI-Data-Code-2002-017.pdf:5.65MB
地球シミュレータ用の可視化システムを開発した。地球シミュレータ上でのシミュレーションと同時にクライアントにおいてその結果を視覚化することができ、計算を行っている最中に、その計算及び可視化の為のパラメータを変更することも可能である。グラフィカルユーザインターフェースはJava appletで構築されており、そのためウェブブラウザさえあればよく、OSに非依存である。本システムはサーバ機能,ポストプロセッシング機能,クライアント機能で構成されている。本稿ではサーバ機能及びポストプロセッシング機能の使い方を中心に報告する。
横川 三津夫; 斎藤 実*; 石原 卓*; 金田 行雄*
ハイパフォーマンスコンピューティングと計算科学シンポジウム(HPCS2002)論文集, p.125 - 131, 2002/01
近年のスーパーコンピュータの発展により、ナビエ・ストークス(NS)方程式の大規模な直接数値シミュレーション(DNS)が可能となってきた。しかし、乱流現象の解明とそのモデル化のためには、さらに大規模なDNSを行う必要がある。ピーク性能40Tflop/sの分散メモリ型並列計算機である地球シミュレータを用いて、大規模なDNSを行うためのスペクトル法を用いたDNSコード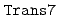 を開発し、既存コードとの比較により本コードの妥当性を検証した。格子点
を開発し、既存コードとの比較により本コードの妥当性を検証した。格子点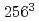 ,1APでの逐次版の実効性能は約3.72Gflop/sが得られた。また、並列版の実効効率は、単体ノードにおいてプロセッサ数にほぼ比例し、AP8台で7倍近い速度向上が得られた。8台のマルチノード環境では、ノード数の増加に伴い速度向上率が低下するが、格子点数
,1APでの逐次版の実効性能は約3.72Gflop/sが得られた。また、並列版の実効効率は、単体ノードにおいてプロセッサ数にほぼ比例し、AP8台で7倍近い速度向上が得られた。8台のマルチノード環境では、ノード数の増加に伴い速度向上率が低下するが、格子点数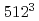 に対しピーク性能の25%の実効性能が得られた。
に対しピーク性能の25%の実効性能が得られた。
横川 三津夫; 斎藤 実*; 萩原 孝*; 磯部 洋子*; 神宮寺 聡*
日本計算工学会論文集, 4, p.31 - 36, 2002/00
地球シミュレータは、640台の計算ノードをクロスバスイッチで結合した分散主記憶型並列計算機である。計算オードは8つのベクトルプロセッサからなる共有メモリシステムである。ピーク性能は40Tflops,主記憶容量は10TBである。地球シミュレータ上のプログラムの実効性能を推定するための性能予測システムGS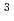 を開発した。GSのベクトル性能の予測精度を確認するために、3グループのカーネルループに対し、GSによる予測値とSX-4の測定値を比較した結果、実行時間の絶対誤差で0.89%,1.42%,6.81%が得られた。地球シミュレータの実効性能を予測した結果、 それぞれのグループで平均5.94Gflops,3.76Gflops,2.17Gflopsが得られた。
を開発した。GSのベクトル性能の予測精度を確認するために、3グループのカーネルループに対し、GSによる予測値とSX-4の測定値を比較した結果、実行時間の絶対誤差で0.89%,1.42%,6.81%が得られた。地球シミュレータの実効性能を予測した結果、 それぞれのグループで平均5.94Gflops,3.76Gflops,2.17Gflopsが得られた。
上原 均
JAERI-Data/Code 2001-010, 41 Pages, 2001/03
JAERI-Data-Code-2001-010.pdf:2.67MB
大規模な数値シミュレーションの実現や数値シミュレーションの高速実行のために、メッセージ通信を用いた分散並列プログラムが開発されている。このメッセージ通信のプログラム仕様として最も主要なものがMPIであり、メッセージ通信を用いた通信部分の性能は、分散並列プログラム全体の性能に直接的に影響する。このMPIは、現在開発中の地球シミュレータ上でも利用が予定されている。このため、MPIの通信性能を詳細に測定し、かつ移植性の高いベンチマークプログラムライブラリ(MPI benchmark program library, 以降MBLと略記)を開発した。MBLでは、ユーザの使用頻度の高い1対1送信関数/集合通信関数の性能測定と、実際のアプリケーションに頻繁に見られる通信パターン時の性能測定を行う。本報告では、このMBLの詳細と、MBLによるNEC SX-4上でのMPIの性能計測結果を示す。
横川 三津夫; 津田 義典*; 斉藤 実*; 末広 謙二*
Proceedings of 4th Annual HPF User Group Meeting (HUG2000), p.124 - 130, 2000/00
地球シミュレータのようなSMPクラスタではメモリ階層を考慮した並列化手法を用いる必要があり、ハイブリッド並列プログラミング手法はSMPクラスタ上で大規模計算を行うときに非常に重要である。一様等方性乱流プログラムTrans6に対し、HPFを用いた並列化を行い、自動並列化による実行時の性能比較を、SX-5を用いて実施した。この結果、8個のHPFプロセスの実行時間は、自動並列化による8個のマイクロタスクの実行時間よりも1.58倍大きいことがわかった。また並列化効率は、HPF,マイクロタスクそれぞれで69.87%,44.35%であった。さらに、マルチノードでのプログラミングを検討するために、1つのHPFプロセスとその中の8個のマイクロタスクによる実行時間を計測した結果、8台で約5倍の性能が得られた。
